


基本信息
- 项目名称:
- 联合编码的免疫克隆选择无监督聚类算法
- 来源:
- 第十二届“挑战杯”省赛作品
- 小类:
- 信息技术
- 大类:
- 自然科学类学术论文
- 简介:
- 由于聚类分析在识别数据内在结构方面所具有的重要作用,已在数据挖掘、模式识别、信息检索等领域得到了广泛应用。一直是国内外相关领域研究的热点问题。本作品针对目前一些聚类算法存在依赖领域知识、效率不高、无法有效处理高维数据集等不足之处,提出了一种新的聚类算法,在一定程度上解决了以上问题。
- 详细介绍:
- 针对聚类数未知的问题,鉴于免疫克隆选择算法的快速收敛性与强大的优化能力,本文将其引入无监督聚类问题中,提出了一种联合编码的免疫克隆选择无监督聚类算法。该算法在引入免疫克隆选择算法思想的基础上,分别设计了一种新的联合编码方案、基于单点变异的免疫基因操作、吞并算子以及基于人工免疫进化网络原理的聚类结果优化方案。通过算法迭代寻优以及根据需求对最优聚类结果的二次优化,最终得到令人满意的聚类结果。
作品图片

作品专业信息
撰写目的和基本思路
- 目的:希望设计一种不但能够自动确定聚类类别数,可推广到高维数据聚类问题,而且能够根据需要对一次聚类结果进行二次优化的高效的聚类算法。 基本思路:鉴于免疫克隆选择算法所具有的快速收敛性和强大的优化能力,本文将其引入无监督聚类问题中,并通过设计新的联合编码方案,基于单点变异策略的免疫基因操作,吞并算子以及基于人工免疫网络原理的聚类结果优化方案使得算法能够达到预期目的。
科学性、先进性及独特之处
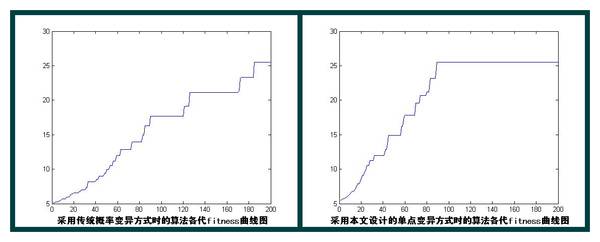
- 1、算法设计了一种新的综合聚类类别数与聚类中心的联合编码方案,有效克服了对领域知识的依赖。 2、提出了一种新的基于单点变异策略的更适合于聚类问题的克隆选择算子,使得算法效率大大提高。 3、借鉴Darwin进化论优胜劣汰思想提出了新的算子--吞并算子,加快了算法的收敛速度。 4、基于人工免疫网络思想,提出利用最小生成树剪枝操作进行聚类结果二次优化过程,已得到最优聚类结果。
应用价值和现实意义
- 本文算法较好地弥补了现有大多数聚类算法应用于实际问题时所暴露出的不足。仿真实验表明,本算法可以很好地处理对人工数据集和遥感图像的聚类分析问题。此外,本算法还可应用于信息检索、数据分析等领域,具有较高的实际应用价值和现实意义。
学术论文摘要
- 摘要 采用一种新的联合编码方式,并引入了免疫克隆选择机制以及人工免疫进化网络的思想,提出了一种联合编码的免疫克隆选择无监督聚类算法。该算法设计了一种综合聚类类别数及聚类中心的编码方式,无需事先指定聚类类别数,有效地克服了对领域知识的依赖。同时,通过免疫克隆算子算法实现聚类结果,并采用最小生成树的方式完成有效地聚类。实验结果表明,该方法能对不同类型的数据集进行正确聚类,并能确定合适的聚类类别。 关键词 联合编码 免疫 克隆选择 无监督聚类 最小生成树
获奖情况
- 论文录用情况: 《Union Coding based Immune Clone Selection Unsupervised Clustering Algorithm》 --2011 International Conference on Computer Application and System Modeling
鉴定结果
- 无
参考文献
- References [1] SUN Ji-Gui , LIU Jie , ZHAO Lian-Yu . New Progress in Clustering Algorithms Research , Journal of Software , Vol.19 , No.1 , January 2008 , pp.48-61. [2] Castro L. N. D , Zuben F. J. V . An Evolutionary Network for Data Clustering Proceedings , Sixth Brazilian Symposium on Neural Networks , 2000 Page(s):84-89. [3] Kim J. , Bentley P. J . Towards an artificial immune system for network intrusion detection : an investigation of clonal selection with a negative selection operator . Proceedings of the 2001 Congress on Evolutionary Computation , 2001 , 2:1244-1252. [4] DU Hai-Feng , JIAO Li-Cheng , WANG S . Clonal Operator and Antibody Clone Algorithms . Proceedings of the First International Conference on Machine Learning and Cybernetics , Beijing , 4-5 November 2002:506-510. [5] Maulik U, Bandyopadhyay S. Genetic algorithm-based clustering technique . Pattern Recognition , 2000 , 33(9):1455-1465.
同类课题研究水平概述
- 现有的聚类算法大致可划分为层次化聚类算法、划分式聚类算法、基于密度和网格的聚类算法以及其他聚类算法。层次化聚类算法使用数据的联接规则,透过一种层次架构方式,反复将数据进行分裂或聚合,以形成一个层次序列的聚类问题解。层次化聚类算法一般以固定数目的点来表示一个聚类,提高了算法挖掘任意形状聚类的能力。划分式聚类算法通过反复迭代降低目标函数的误差值,当目标函数值收敛时,得到最终聚类结果。基于密度的聚类算法通过数据密度来发现任意形状的类簇,而基于网格的聚类算法使用一个网格结构,围绕模式组织由矩阵块划分的值空间,基于块的分布信息实现模式聚类。基于网格的聚类算法常常与其他聚类算法相结合,特别是与基于密度的聚类算法相结合。基于密度和网格的聚类算法的主要优点是能够发现任意形状的聚类以及对数据不敏感。 在传统的聚类方法中,基于目标函数的聚类算法把聚类问题归结为一个优化问题,具有深厚的泛函基础,从而成为聚类算法的主流。K-means聚类算法就是其中最具代表性的一种。该算法效率比较高,但由于聚类目标函数是高度非线性和多峰的函数,因此标准的K-means聚类算法在使用其hill-climbing方式优化目标函数时,搜索方向总是沿着单一方向进行,算法易陷入局部最优点。这种基于目标函数的聚类算法存在的主要问题就是对聚类领域知识要求的增加。在聚类分析之前必须给定聚类类别数,否则将会对算法产生误导,从而得到一个错误的划分。但是,在实际应用中,尤其是当数据样本点处于高维空间时,很难获得聚类类别数。另一方面,为了克服一些算法(如K-means聚类算法)易陷入局部最优点的问题,Maulik提出了遗传聚类算法(GAC),通过进化的思想不断优化聚类中心,能够较好克服算法陷入局部最优点的问题。但是,Maulik的遗传聚类算法直接将聚类中心编码为个体,这样的编码方式与维数相关,很难直接推广到高维数据聚类问题。现有大多数聚类算法对数据集进行聚类分析时产生一次聚类结果,无法根据需求对一次聚类结果进行修改,如要对一次聚类结果进行修改,只能通过改变聚类类别数等参数重新进行聚类。而在实际应用中,我们通常希望可以根据一次聚类分析后得到的聚类结果并结合实际需求对一次聚类结果进行简单修改后便可得到我们期望的最终聚类结果,而不是修改参数重新进行一次聚类分析。