基于图像识别技术的甲骨文数据系统
作者:白钰卓 计算机系
指导老师:刘知远 计算机系
关键词:甲骨文 数据库 图像识别
摘要
本项目致力于使用计算机技术构建甲骨文数据库与甲骨文单字识别系统,并通过公开数据平台向社会共享项目成果。首先,我们通过对现有甲骨文资料进行处理,获得单字与甲片双向对应的细粒度序列化甲骨文数据库,为后续研究打下基础;此后,我们基于图像识别技术实现甲骨文单字识别,提高甲骨文数据电子化的效率,并为古文字学专家提供参考;完成前两步后,我们搭建了公开网站,整合了包含甲片和单字的数据库与单字识别接口,向社会共享我们的研究成果。
项目背景
甲骨文是中国殷商时期的成熟文字系统,是已知的最早汉字形态。其破译与释读是挖掘甲片史料信息的先决条件,但其中的定字环节遇到了极大困难——由于刻划复杂以及甲片记载信息缺失,学者考据时会联系各部分材料反复比对。因此古文字学者常需要熟记众多大部头著录,深耕领域数十年才能做出成果,这使得青年人才望而却步,甲骨文成为冷门绝学。本项目分为甲骨文数据库构建、甲骨单字识别及公开平台搭建三部分,希望降低甲骨文研究门槛,便利古文字学者,也希望对破译更多甲骨文提供参考,推动古文字学进展,为传承优秀传统文化作出贡献。
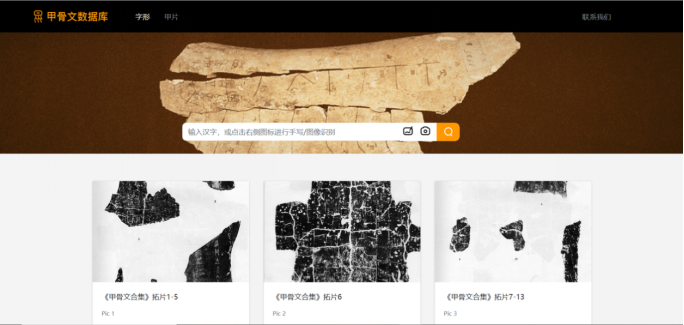
图1 甲骨文公开数据库平台
甲骨文公开数据库
依托现有甲骨文考证与编纂资料,本项目构建了甲骨文单字与甲片的公开数据库。一方面,通过对《殷墟甲骨文摹释全编》进行数字化,本项目获得了以规范摹写字形式书写的细粒度语料库,其中包含《甲骨文全集》前5000张甲片的单字级别序列化内容及对应的现代汉字翻译,此部分数据应为目前公开的最大规模的甲骨文序列化数据库;另一方面,通过对《新甲骨文编》进行数字化,本项目获得了各甲骨文单字来自真实场景的不同字形拓写字集合,丰富了现存语料的种类,拓展了数据库的应用场景。综合两方面数据,并实现了同字对应后,数据库中实现了单字拓写字、摹写字、对应汉字、序列化语句、甲片图片的多向检索,为甲骨学研究提供了有力的支撑,细粒度语料也是基于序列化数据的甲骨文语言模型不可或缺的要素。
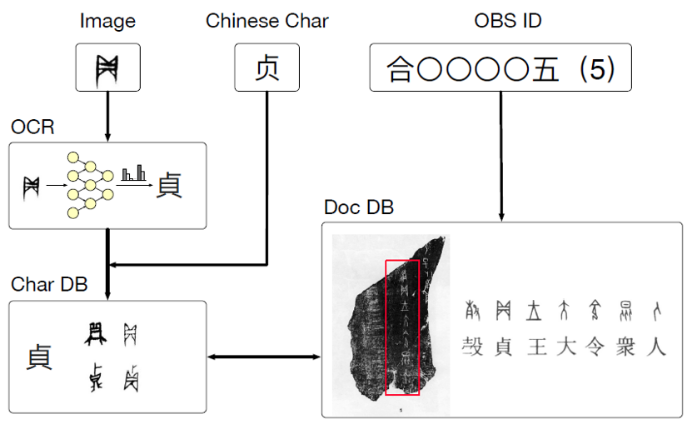
图2 数据库架构
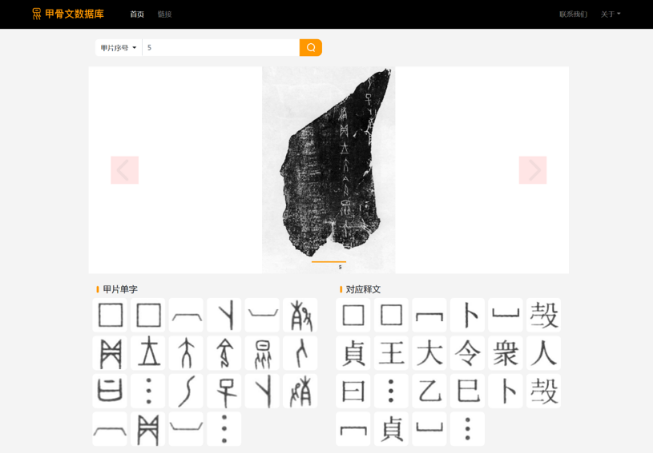
图3 公开数据平台甲片文档展示
甲骨文单字识别系统
本项目以甲骨文数据库中的甲片拓写字为数据集,搭建了甲骨文识别系统。由于部分甲骨文单字的数据较少,本项目采用了few-shot learning的方式训练识别模型,并对Prototypical Network等三个常用于few-shot learning与文字识别的模型进行了对比,以选出最佳模型。最终采用的模型在每个甲骨文单字拥有超过12个拓写样本的甲骨文数据集上可以达到81.4%的正确率,而在整体数据集上(超20000个样本,其中包含1000余个只有2-11个样本的单字)达到了63.9%的正确率,说明模型具有较强的泛化能力。
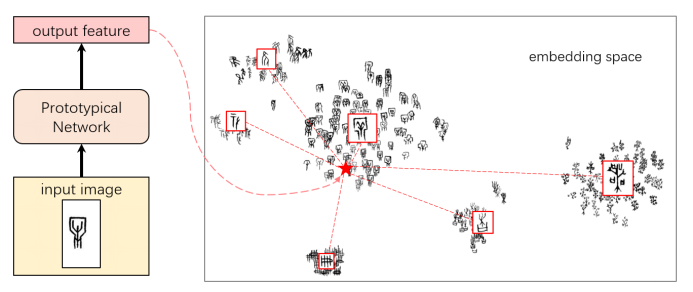
图4 ProtoNet示意图
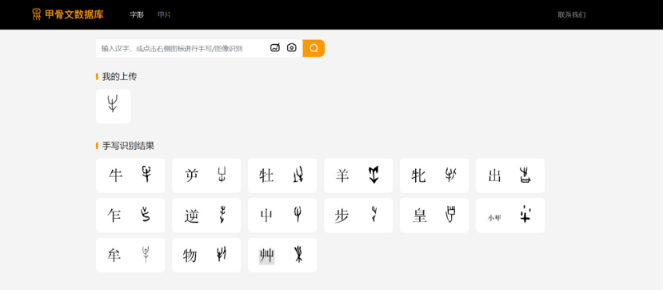
图5 公开数据平台单字搜索结果
外部链接:公开数据平台网址http://123.56.70.83:8080/




