


基本信息
- 项目名称:
- 文献检索与管理系统bibEOS
- 来源:
- 第十一届“挑战杯”国赛作品
- 小类:
- 信息技术
- 大类:
- 科技发明制作B类
- 简介:
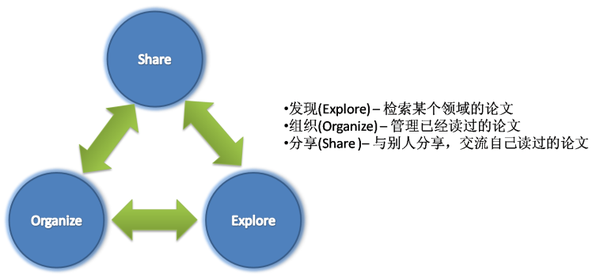
- bibEOS(bibliography Explore, Organize and Share)系统是一个Web 2.0式的论文检索与管理系统。本系统提供的论文检索与管理机制能够使用户通过友好的用户界面高效地获得有质量保证的论文检索结果,并且能够对检索的论文加以有效地管理,同时可以和同行交流论文阅读的心得。 bibEOS系统一方面建立支持多种灵活查询方式的论文搜索引擎,在论文搜索引擎上帮助研究者获取隐藏在数据中的有用的知识,即论文检索功能;另一方面,帮助研究者管理和分享已获得的知识,为研究者提供一个交流与共享知识的平台,即论文管理功能。 bibEOS系统的目标是为研究者提供一个Explore, Organize and Share 知识的系统。
- 详细介绍:
- 研究者在进行研究工作时需要经常需要完成下面的工作:在现有的论文搜索引擎上帮助研究者发现隐藏在数据中的有用的知识,组织已获得的知识,分享交流已获得的知识。 基于以上分析,bibEOS(bibliography Explore, Organize and Share)系统一方面建立支持多种灵活查询方式的论文搜索引擎,在论文搜索引擎上帮助研究者获取隐藏在数据中的有用的知识,即论文检索功能;另一方面,帮助研究者管理和分享已获得的知识,为研究者提供一个交流与共享知识的平台,即论文管理功能。这对帮助研究者提高研究工作效率有着重要的意义。 为了让研究者从查询中获得更多的有价值的信息,论文检索不仅支持基于属性关键字的传统检索方式,还支持查询隐藏在数据中的有用的知识,例如作者之间的合作关系和论文之间的引用关系等,这些知识能够从一定程度上反映出论文的背景信息和论文的重要程度。论文管理帮助研究者对从论文检索中获得的知识进行有效地管理,如收藏信息,并对该信息进行自由地分类和评论;同时也帮助研究兴趣相同的研究者之间共享信息。 为了有效地实现论文管理,本系统选用XML作为论文管理的数据形式,利用了XML的半结构化、易理解性和可扩展性,将用户对所收藏的信息进行的添加、修改、删除操作转化为对XML标签和数据的操作,极大地方便用户管理数据。 在论文信息管理中,我们采用了实体识别、社团发现、数据清洗等技术,提高了系统中数据的质量,为用户提供高质量的检索结果。 bibEOS系统是一个基于B/S结构的论文检索与管理系统。本系统提供的论文检索与管理机制能够使用户通过友好的用户界面高效地获得有质量保证的论文检索结果,并且能够对检索的论文加以有效地管理,同时可以和同行交流论文阅读的心得。因而,该系统可以大大提高科研工作者工作效率、加强科研工作者交流,对推动科学研究的发展有着重要的意义。
作品图片
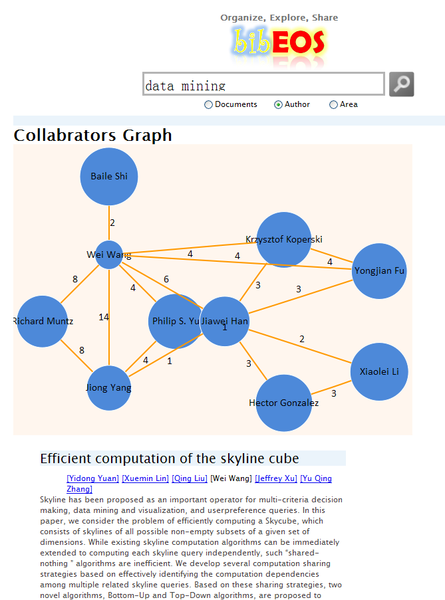
作品专业信息
设计、发明的目的和基本思路、创新点、技术关键和主要技术指标
- 设计该作品是为了通过对论文信息的查询、管理和共享来帮助研究者进行研究工作。基本思想是利用数据清洗、实体识别和数据挖掘的先进技术来提高数据的质量、过滤掉对研究者没有意义的数据以及帮助研究者发现隐藏在大量论文中的有用的统计信息,提高查询的功能。除此以外,该作品有机结合了论文检索、论文管理以及信息共享等功能,方便用户在查询到信息以后方便及时地对信息进行管理和共享。
科学性、先进性
- 1. 本系统不仅提供了通常搜索引擎基于关键字合作者检索论文的功能,还提供了基于领域检索论文的功能 2. 本系统对重名作者进行了识别,提高了检索结果的质量 3. 本系统提供了论文管理的功能,方便用户将论文检索的结果添加标签并加以存储 4. 本系统在论文管理中提供了标签机制,利用Web2.0的思想使得检索结果和用户之间得以交互 5. 本系统地提供了组功能,使具有相同兴趣的用户可以进行沟通 6. 本系统设计了数据清洗机制对从数据源提取的信息加以清洗,提高了数据质量 7. 为了有效地实现论文管理,本系统选用XML作为论文管理的数据形式,利用了XML的半结构化、易理解性和可扩展性,将用户对所收藏的信息进行的添加、修改、删除操作转化为对XML标签和数据的操作,极大地方便用户管理数据。
获奖情况及鉴定结果
- 无
作品所处阶段
- 实验室阶段
技术转让方式
- 以网站的形式发布
作品可展示的形式
- 现场演示、录像
使用说明,技术特点和优势,适应范围,推广前景的技术性说明,市场分析,经济效益预测
- 1. 本系统将论文检索与论文管理相结合,不仅能够帮助科研人员高效地获得有质量保证的论文检索结果,还能够对检索的论文加以有效地管理,同时可以和同行交流论文阅读的心得。因而,该系统可以大大提高科研工作者工作效率、加强科研工作者交流,对推动科学研究的发展有着重要的意义 2. 本系统以XML的形式存储大量的论文信息,利用XML的灵活性和可扩展性,极大地简化了数据管理的复杂性,提高了论文检索和管理的效率 3. 在论文信息管理中,本系统采用了实体识别、社团发现、数据清洗等技术,提高了系统中数据的质量,为用户提供高质量的检索结果
同类课题研究水平概述
- 在文献检索时,存在作者重名的问题,因此需要对作者实体进行识别。而实体识别技术在六十年代已经开始研究,[1]是对实体识别技术的综述。实体识别问题在过去被称为记录链接或记录匹配问题。记录匹配的目标是识别在相同或不同的数据库里对应现实世界中相同的实体。这个问题还被不同的研究领域命为许多其他的名字。在数据库领域,这个问题被称作合并清除[2],数据去重[3],和实例识别[4]。而在我们的系统里不是对数据库里的元组进行实体识别,而是对XML文档里的作者进行实体识别。 当前的文献检索系统都是基于文件系统进行关键字检索的,在我们的系统里首次采用了xml数据与关系数据类型混合的数据库来存储数据。 References [1] Ahmed K. Elmagarmid, Panagiotis G. Ipeirotis, Vassilios S. Verykios, "Duplicate Record Detection: A Survey," IEEE TKDE, vol. 19, no. 1, Jan. 2007. [2] M.A. Herna´ndez and S.J. Stolfo, "Real-World Data Is Dirty: Data Cleansing and the Merge/Purge Problem," Data Mining and Knowledge Discovery, vol. 2, no. 1, pp. 9-37, Jan. 1998. [3] S. Sarawagi and A. Bhamidipaty, "Interactive Deduplication Using Active Learning," KDD 2002, pp. 269-278. [4] Y.R. Wang and S.E. Madnick, "The Inter-Database Instance Identification Problem in Integrating Autonomous Systems," Proc. Fifth IEEE Int’l Conf. Data Eng. (ICDE ’89), pp. 46-55, 1989.